


Personally identifiable information (PII) and personal data both refer to information that can reveal who someone is – but they’re not the same thing, and mixing them up can have real compliance consequences.
PII is a US-centric term with no single legal definition. Personal data is a precise legal term defined by the GDPR across the EU. Both cover information that can identify a person directly or indirectly, but their scope, legal coverage, and implications differ significantly.
This guide explains both concepts, how they relate to non-PII and non-personal data, and what your organization needs to do to stay compliant.
Key takeaways
- PII is mainly used in the US but has no single legal definition; personal data is a legal term defined by GDPR in the EU.
- Both cover information that can directly or indirectly reveal an individual’s identity.
- PII is divided into linked (direct identifiers) and linkable (indirect identifiers) information.
- Personal data includes online identifiers like cookies and IP addresses under GDPR.
- Cookies and device IDs are considered PII under NIST and personal data under GDPR – but some AdTech companies still classify them as non-PII.
- Legal requirements are getting stricter globally; what counts as protected data keeps expanding.
- Protecting PII and personal data reduces breach risk, builds customer trust, and keeps you compliant.
Table of contents
- Key takeaways
- What is personally identifiable information (PII)?
- What pieces of information are considered PII?
- What is personal data?
- What is non-personal data?
- How PII differs from personal data
- Why should you protect PII and personal data?
- PII, non-PII, and personal data: Staying up to date on data privacy regulations
- Frequently asked questions
What is personally identifiable information (PII)?
Quick answer: PII is any information that can be used to identify an individual – either on its own or in combination with other data. The most widely used definition comes from the US National Institute of Standards and Technology (NIST).
Personally identifiable information (PII) is often referenced by US government agencies and non-governmental organizations. However, because the US lacks one overriding law about PII, the definition may vary from jurisdiction to jurisdiction and state to state.
The most common definition is provided by the National Institute of Standards and Technology (NIST):
PII is any information about an individual maintained by an agency, including (1) any information that can be used to distinguish or trace an individual’s identity, such as name, social security number, date and place of birth, mother’s maiden name, or biometric records; and (2) any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information.
The line between PII and other kinds of information is not always clear. As the US General Services Administration points out, the definition of PII requires “a case-by-case assessment of the specific risk that an individual can be identified” – it isn’t tied to any single category of information or technology.
What pieces of information are considered PII?
According to NIST, PII falls into two main categories: linked and linkable information.
Linked information
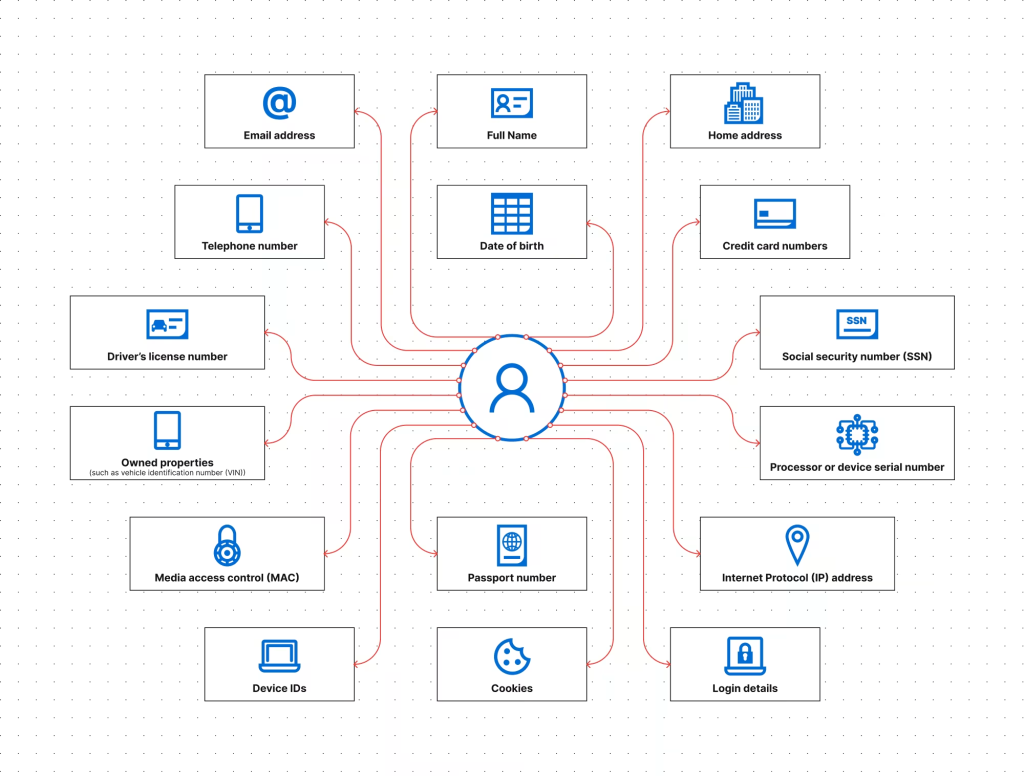
Linked information (also called direct identifiers) is unique to a person and can be used to identify an individual on its own. A single direct identifier is typically enough to determine someone’s identity.
Examples of linked information include:
- Full name
- Social security number (SSN)
- Driver’s license number
- Passport number
- Biometric data (fingerprints, retinal scans)
- Financial account numbers
- Medical record numbers
NIST also includes “asset information, such as Internet Protocol (IP) or Media Access Control (MAC) address or other host-specific persistent static identifier that consistently links to a particular person or small, well-defined group of people” – which means cookies and device IDs fall under the definition of PII.
Linkable information
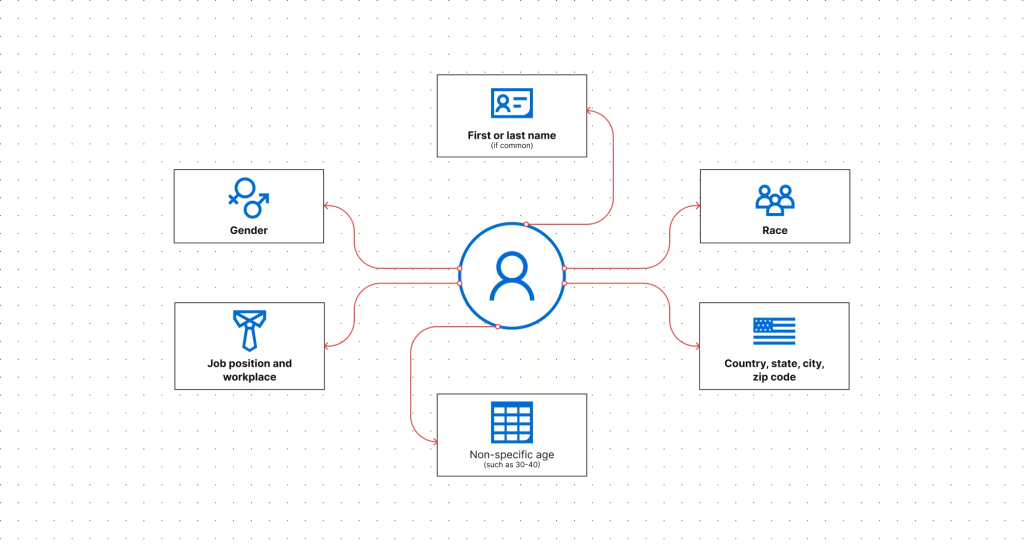
Linkable information (also called indirect identifiers or quasi-identifiers) cannot always identify a person on its own, but can when combined with other data.
For example, research shows that 87% of US citizens could be identified based solely on their gender, ZIP code, and date of birth. De-anonymization techniques typically work by connecting multiple quasi-identifiers.
Examples of linkable PII include:
- Job title or position
- Non-specific age range
- Workplace name
- General geographic area
- Religious affiliation
- Race or ethnicity
Sensitive vs. non-sensitive PII
Though more of a customary than regulatory distinction, PII can also be divided into sensitive and non-sensitive types.
Sensitive PII
Sensitive PII can directly identify an individual and could cause harm if exposed in a data breach. It is typically not publicly available, and many data privacy laws require organizations to encrypt it and restrict access.
Examples of sensitive PII:
- Government-issued ID numbers (SSN, driver’s license, passport)
- Biometric data (fingerprints, retinal scans)
- Financial information (bank account numbers, credit card numbers)
- Medical records
- Electronic account information (email addresses, account numbers)
- Employee personnel records
- Passwords
- School identification numbers
Non-sensitive PII
Non-sensitive PII may or may not be unique to a person, can be transmitted without encryption, and disclosure typically won’t cause direct harm.
Non-sensitive PII tends to be publicly available – for example, phone numbers listed in a directory.
Examples of non-sensitive PII:
- Full name
- Mother’s maiden name
- Social media username
- Telephone number
- IP address
- Place of birth
- Date of birth
- Geographic details (ZIP code, city, state)
- Employment information
- Email or mailing address
- Race or ethnicity
- Religion
note
Some regulations don’t require protection of non-sensitive PII, but organizations should still apply safeguards to minimize risk to individuals.
How PII differs from PHI
Quick answer: Protected health information (PHI) is a subset of PII that applies specifically to health data processed by HIPAA-covered entities. All PHI is PII, but not all PII is PHI. When health information is combined with a personal identifier, it becomes PHI – and is subject to strict HIPAA rules.
Protected health information (PHI) is any identifiable data about a patient – including name, address, date of birth, SSN, device identifiers, email addresses, biometrics, lab results, medical history, and payment information – that is processed by a HIPAA-covered entity.
Electronically protected health information (ePHI) is PHI that is created, received, used, or maintained in electronic form. Most modern healthcare analytics involves ePHI.
HIPAA-covered entities include health plans, healthcare clearinghouses, and healthcare providers, as defined in the HIPAA Privacy Rule. Their business associates are also bound by HIPAA requirements.
Identifiable health information is not considered PHI unless it is held by a HIPAA-covered entity. However, once health information is combined with any personal identifier from the list below, it becomes PHI regardless of context.
The Department of Health and Human Services (HHS) recognizes 18 HIPAA identifiers:
- Names
- All geographic subdivisions smaller than a state (street address, city, county, ZIP code)
- Dates (other than year) – including birthdate, admission date, discharge date, date of death
- Telephone numbers
- Fax numbers
- Email addresses
- Social security numbers
- Medical record numbers
- Health plan beneficiary numbers
- Account numbers
- Certificate or license numbers
- Vehicle identifiers and serial numbers, including license plate numbers
- Device identifiers and serial numbers
- Web URLs
- IP addresses
- Biometric identifiers, including fingerprints and voice prints
- Full-face photographs
- Any other unique identifying number, characteristic, or code
Piwik PRO provides fully HIPAA-compliant analytics. We sign BAAs with healthcare organizations, allowing you to securely collect and analyze PHI and ePHI. If you prefer, you can also de-identify PHI before sending it to our platform. Learn more: HIPAA-compliant analytics with Piwik PRO
Learn more: PHI and PII: How they impact HIPAA compliance and your marketing strategy
What is non-PII?
Quick answer: Non-PII is data that cannot be used on its own to trace or identify a person.
Non-personally identifiable information (non-PII) includes:
- Aggregated statistics on the use of a product or service
- Partially or fully masked IP addresses
However, the classification of PII and non-PII is not always clear-cut. Because NIST doesn’t explicitly reference cookie IDs and device IDs, many AdTech companies, advertisers, and publishers consider them non-PII. This contrasts with the GDPR definition of personal data, which treats digital trackers as potential identifiers. This discrepancy is one of the most common sources of compliance confusion.
What is personal data?
Quick answer: Personal data is any information that relates to an identified or identifiable living person. Under the GDPR, this includes not just names and ID numbers, but also online identifiers like IP addresses and cookies.
Personal data is defined in GDPR Article 4(1) as:
‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.
Under GDPR, cookies are considered personal data. GDPR Recital 30 explains that online identifiers like IP addresses and cookie IDs may be used to create profiles and identify individuals, particularly when combined with unique identifiers and server data.
Examples of personal data include:
- Transaction history
- IP addresses
- Browser history
- Posts on social media
- Cookies and device identifiers
- Location data
Essentially, it covers any information – directly or indirectly – that relates to an identifiable individual.
What is non-personal data?
Non-personal data is data that cannot be used to identify an individual. Under GDPR Recital 26, anonymous data – information rendered anonymous in such a manner that the data subject is no longer identifiable – falls outside the scope of data protection rules.
Examples of non-personal data:
- Generalized data, such as age range
- Government or municipal data (census data, tax receipts for public works)
- Aggregated product or service usage statistics
- Partially or fully masked IP addresses
Collecting anonymous data allows companies to gain analytics insights without accessing personal data – this is possible with Piwik PRO Analytics Suite.
Learn more: Anonymous tracking: How to do useful analytics without personal data
How PII differs from personal data
Personal data is broader than PII. All PII is personal data, but not all personal data is PII. For example, attributes like religion, ethnicity, sexual orientation, or medical history may be personal data without necessarily qualifying as PII under certain US frameworks.
| PII | Personal data | |
|---|---|---|
| Identification of individuals | Often used to differentiate one individual from another | Includes any information related to a living individual, whether it distinguishes them or not |
| Type of term | Not a legal term; commonly used in business | Legal term defined by GDPR |
| Legal coverage | Various laws at federal, state, and sector levels | Single set of EU-wide laws |
| Regulated information | May cover only specific kinds of privacy and data access | Regulates all facets of information privacy and use |
| Territorial application | Primarily the US | Primarily the EU |
| Legal characteristic | Each organization or government provides specific laws | Unified approach to data security and privacy enforcement |
| Individual rights | Vary by regulation; may not cover all rights | Standardized: right to access, rectification, erasure, portability, restriction of processing |
Key US laws and standards that define PII include:
- The US Privacy Act – governs how to collect, maintain, use, and share PII
- HIPAA – governs patient health information
- COPPA – protects children under 13
Regulatory bodies involved include the FTC, FCC, NIST, and the Network Advertising Initiative (NAI).
Personal information (PI) and the CCPA
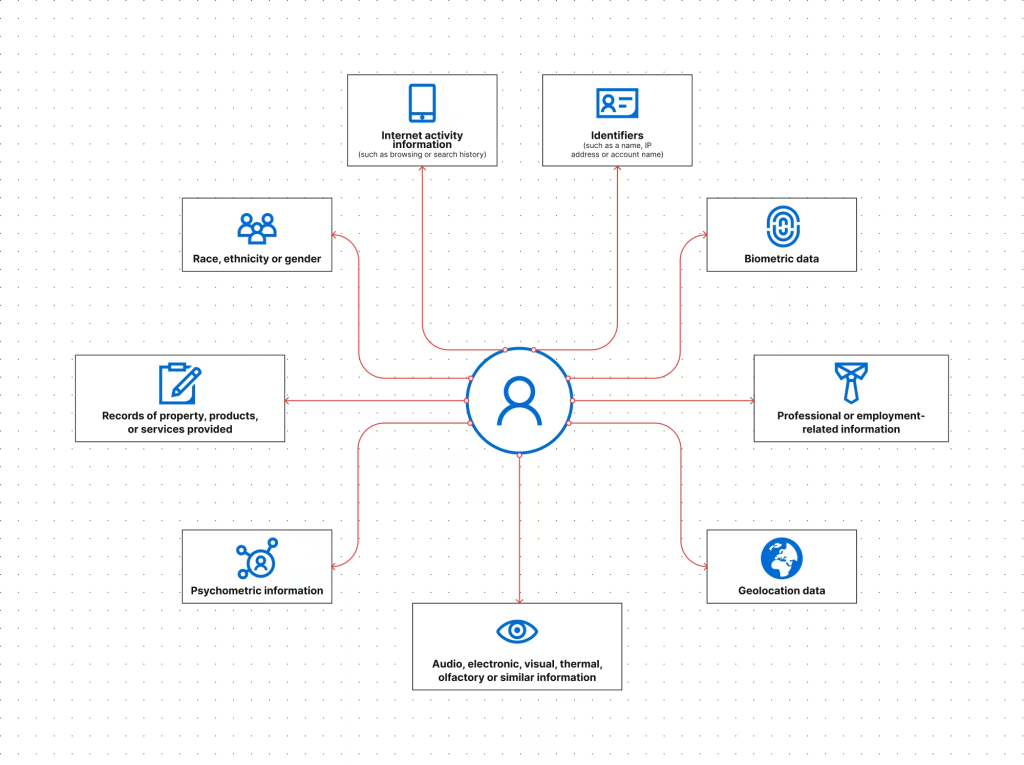
Personal information (PI) is used in the context of the California Consumer Privacy Act (CCPA) and its successor, the California Privacy Rights Act (CPRA).
California defines PI as: “Information that identifies, relates to, describes, is capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household” – excluding information already made publicly available by the government.
Under CCPA, device IDs, cookies, IP addresses, aliases, and account names all qualify as personal information. This broad definition aligns more closely with GDPR’s personal data than with NIST’s definition of PII.
Why should you protect PII and personal data?
Organizations collect PII to personalize experiences and improve products – but the growing volume of stored PII also makes organizations targets for cyberattacks.
Stolen PII can be used to open fraudulent accounts, take out loans, create fake passports, or sell someone’s identity. Data breaches affect organizations of every size and industry, with significant consequences:
- Loss of customer trust and reputational damage
- Regulatory fines for non-compliance
- Financial losses from breach remediation
According to IBM’s Cost of a Data Breach 2025 Report, the average cost of a ransomware-related data breach was USD 5.13 million. ESG research found that the volume of sensitive data approximately doubled between 2021 and 2024, while around half of organizations believe that data is not sufficiently secure.
Proactively protecting PII and personal data doesn’t just reduce risk – it builds customer loyalty, demonstrates accountability, and futureproofs your tech investments against tightening regulations.
How to protect PII
The primary guidance for securing PII comes from NIST’s Guide to Protecting the Confidentiality of Personally Identifiable Information (SP 800-122).
NIST recommends a combination of three types of measures:
Operational safeguards
Operational safeguards address how your organization manages PII at a process level:
- Establish clear policies and procedures for handling PII
- Train employees on data breach risks and best practices
- Implement data minimization – collect only what’s necessary
Privacy-related safeguards
Privacy-specific safeguards help organizations follow the data minimization principle and protect data confidentiality:
- Data anonymization
- De-identification and pseudonymization (e.g., encryption, masking)
- Purpose limitation – only use data for the reason it was collected
Security controls
NIST’s recommended security controls include:
- Access enforcement – grant access based on role
- Remote access controls – restrict PII access during remote sessions; ensure encryption
- Separation of duties – users who handle de-identified PII shouldn’t also have access to re-identification keys
- System monitoring – flag unusual transfers or events involving PII
- Least privilege – limit access to only the data each user needs
- Audit review – regularly review logs for unusual activity
The level of protection required depends on several factors: how easily the PII can be tied to an individual, how many individuals’ data is stored, the sensitivity of the data, the context of use, and applicable legal requirements.
How to protect personal data
The GDPR establishes five key principles for protecting personal data:
The principle of lawfulness
You must have a clear and valid legal basis for collecting and using personal data – for example, contract necessity, a legal obligation, or legitimate interests.
The principle of integrity and confidentiality
Data must be kept secure. The specific safeguards will vary: a hospital handling patient records has different requirements than a blogger managing a newsletter.
Data protection by design
Technical and organizational privacy measures must be built into systems from the initial design phase – not added as an afterthought. Examples include:
- Pseudonymization (encryption, scrambling, masking)
- Anonymization
- Ongoing monitoring of data processing
- Regular privacy feature updates
Note: Under GDPR, pseudonymization alone does not constitute full anonymization.
Data protection by default
Data collection and processing should follow the principles of data minimization and purpose limitation:
- Collect only the minimum data necessary
- Specify and document your processing purpose before collection begins
- Retain data only as long as necessary to fulfill that purpose
Data protection impact assessment (DPIA)
A DPIA is recommended when processing may pose a high risk to individuals. Consider running one when:
- Using a new technology
- Processing sensitive data at scale
- Conducting systematic monitoring of public areas
PII, non-PII, and personal data: Staying up to date on data privacy regulations
The definitions of PII and personal data are expanding. Digital identifiers like cookies and device IDs are increasingly treated as identifying data across regulatory frameworks. The line between PII and non-PII is becoming harder to draw. And privacy requirements are tightening on both sides of the Atlantic.
For organizations, this means taking a closer look at the data they collect, applying appropriate safeguards, and keeping pace with a rapidly evolving legal landscape.
Want to learn more about how Piwik PRO helps you safely collect and analyze PII and personal data?

read also
Learn how to protect PII, non-PII and personal data
Everything from the detailed definition of each to practical approaches to collecting and working with different types of data
Frequently asked questions
What is PII?
Personally identifiable information (PII) is any information that can be used to identify a specific individual – either directly (like a name or SSN) or when combined with other data (like ZIP code and date of birth). In the US, the most widely cited definition comes from NIST.
What’s the difference between PII and personal data?
PII is primarily a US concept with no single legal definition. Personal data is a legal term defined by the EU’s GDPR. Personal data is broader – all PII is personal data, but not all personal data qualifies as PII. For example, a person’s religion or sexual orientation may be personal data without being PII under certain US frameworks.
What’s the difference between sensitive and non-sensitive PII?
Sensitive PII can directly identify a person and could cause harm if exposed – such as SSNs, biometric data, financial records, and medical information. Non-sensitive PII is often publicly available and less likely to cause harm if disclosed, such as a full name, phone number, or date of birth.
Do cookies count as PII or personal data?
Under GDPR, cookies are personal data because they can be combined with other identifiers to profile and identify individuals. Under NIST’s definition, cookies and device IDs can also qualify as PII. However, many AdTech companies still classify them as non-PII – a position that’s increasingly at odds with regulatory trends.
What is the difference between PII and PHI?
Protected health information (PHI) is a subset of PII that applies specifically to health data processed by HIPAA-covered entities (healthcare providers, hospitals, insurers, and their business associates). All PHI is PII, but PII that isn’t health-related is not PHI.
What is non-PII?
Non-PII is data that cannot identify a person on its own – such as aggregated usage statistics or fully masked IP addresses. The boundary between PII and non-PII is blurry, and what’s considered non-PII under one framework may be PII under another.
How can I protect PII in my organization?
NIST recommends a combination of operational safeguards (policies, staff training, data minimization), privacy-related safeguards (anonymization, pseudonymization), and security controls (role-based access, encryption, audit logging). The appropriate level of protection depends on the sensitivity of the data and applicable regulations.
Is consent always required to collect PII?
Not always. Under the CCPA/CPRA, notice and opt-out rights are typically required rather than explicit consent. Under GDPR, consent is one of six valid legal bases – others include contract necessity, legal obligation, and legitimate interests. When consent is required, it must be freely given, specific, informed, and unambiguous.
Related posts:
- PHI vs PII in HIPAA: Healthcare marketing compliance guide
- Anonymous tracking: How to do useful analytics without personal data
- Is Google Analytics GDPR-compliant?
- CCPA & CPRA regulations: How marketers can comply with the Californian laws
- What is first-party data and how does it benefit your marketing strategy


