


The summary
- Server-side tracking sends data directly from your website server to MarTech platforms, bypassing browsers. It ensures better data accuracy, data governance, and improved security, but at the same time it demands significant development effort.
- Server-side tagging relies on a dedicated tag manager server to handle data, providing more control and improved privacy. At the same time, it requires considerable setup and maintenance efforts.
- Hybrid server-side data collection methods, known from tools such as Google Tag Manager and Google Analytics 4, share some benefits of the pure server-side method and are easier to use thanks to the flexibility of client-side setup.
- Both server-side tracking and tagging improve data reliability and work around some client-side limitations but shouldn’t be used without visitor consent.
For years, companies have used client-side tags and pixels to track website visitors, enhance user experiences, measure conversion rates, and target ads. However, the increasing use of ad blockers and the decreasing support for third-party tracking in browsers make client-side methods more challenging. Companies seeking accurate data on user behavior are exploring alternatives, with server-side data collection being a promising solution to their problems.
That said, server-side methods can be confusing as they take various forms and shapes. This article aims to clear up common misconceptions about server-side data collection and explain the differences between tracking methods.
With Piwik PRO you can use integration with Google Tag Manager to collect data server-side and client-side.
A quick disclaimer: For better clarity, in this article we will refer to the methods relying on both client-side and server-side components as hybrid server side tracking and/or tagging. At the same time, the methods fully reliant on a server-side setup will be called pure server-side tracking and/or tagging.
What is server-side tracking?
To explain the mechanisms of server-side tracking, let’s first compare it to the default client-side tracking implementation.
What is client-side tracking?
Client-side tracking collects data by sending information from the user’s browser (the client) directly to an external server, like your analytics account (for example, yoursite.piwik.pro). This is done by adding small pieces of JavaScript code, called tags, to each page of your website. These tags are usually managed through a tag management system.
In server-side tracking, on the other hand, both sending tracking requests and data collection takes place on the server, without the involvement of the browser. The data is then sent from the server to a chosen tool, such as your analytics platform, to populate your reports and dashboards.
The methods of server-side data collection
Although server-side tracking might seem new, it dates back to the early 1990s and the beginnings of web analytics. Known as log analytics, it involved fetching access log files from the company’s website servers. This method provided basic insights into website visitors, such as location, device, referrer site, and browser. Although complex and tiresome, it was better than having no data at all.
Luckily, a lot has changed since then, with modern methods of server-side analytics offering much better convenience and data quality.
Pure server-side tracking deployment
A typical modern server-side implementation is a method in which all data collection happens outside the browser. Instead, the communication takes place directly between a website server and a marketing platform, such as analytics.
The integration between your website server and a marketing platform is usually done using application programming interfaces (API) or software development kits (SDK). APIs allow your server to send data to the marketing platform, while SDKs help build these API queries using predefined functions.
This method provides more control over data collection and processing, enhancing security by removing the impact of client-side deployment. You also get complete freedom in choosing the kind of user identifier you’d like to use – cookies, fingerprinting, and more.
Finally, it allows combining data from various sources, enriching overall data collection.
However, implementing this kind of tracking requires a complex setup and significant development effort. This makes it more suitable for businesses with larger, more advanced development teams.
Advantages of pure server-side analytics tracking
Data accuracy and cookies longevity
It reduces the data loss experienced with client-side trackers, might extend the lifetime of cookies, and gets around client-side limitations, leading to more reliable and comprehensive data. Because it’s based on a 100% server-side configuration, it provides the highest quality of data compared to other modern server-side methods.
Data governance
It provides better control over data, ensuring only necessary data is collected and most types of sensitive information are not shared in the browser. That said, it might still require the use of a personal identifier, for example a visitor cookie ID to recognize visitors across sessions.
Enhanced security
Sensitive data is handled more securely on the server, minimizing the risk of exposure on the client side.
Important considerations of pure server-side tracking
GDPR and consent requirements
It’s important to emphasize that moving your tracking server-side doesn’t make your data collection privacy-compliant. You still need to follow the same rules as with client-side tracking: either collect valid visitor consents or fully anonymize your data.
Development effort
Implementing server-side tracking requires significant development effort. Integrating SDKs or APIs into the server, setting up data processing, and maintaining the infrastructure can be complex and time-consuming. Smaller teams or organizations might find it challenging to allocate the necessary resources.
Server costs
Maintaining the server infrastructure to handle server-side tracking can also be expensive. As data volumes increase, you may need to scale your server infrastructure, which can further increase costs and complexity.
Example tools for pure server-side tracking
- Piwik PRO Analytics Suite
- Matomo
- Google Analytics 4
- Any other analytics platform with available APIs and SDKs
Hybrid server-side tracking with a first-party collector
Hybrid server-side tracking methods combine the convenience of client-side data collection with the control, security, and flexibility of server-side tracking. However, they offer a slight compromise in data accuracy since they still partly rely on the browser. Despite this, hybrid methods are much more reliable than a purely client-side setup.
In server-side tracking with a first-party collector, data is sent to one primary place, usually an analytics platform. The tracking requests to the browser come from your website’s domain (or subdomain) instead of a third-party platform. The data then goes through a proxy server on your web server before reaching the analytics platform.
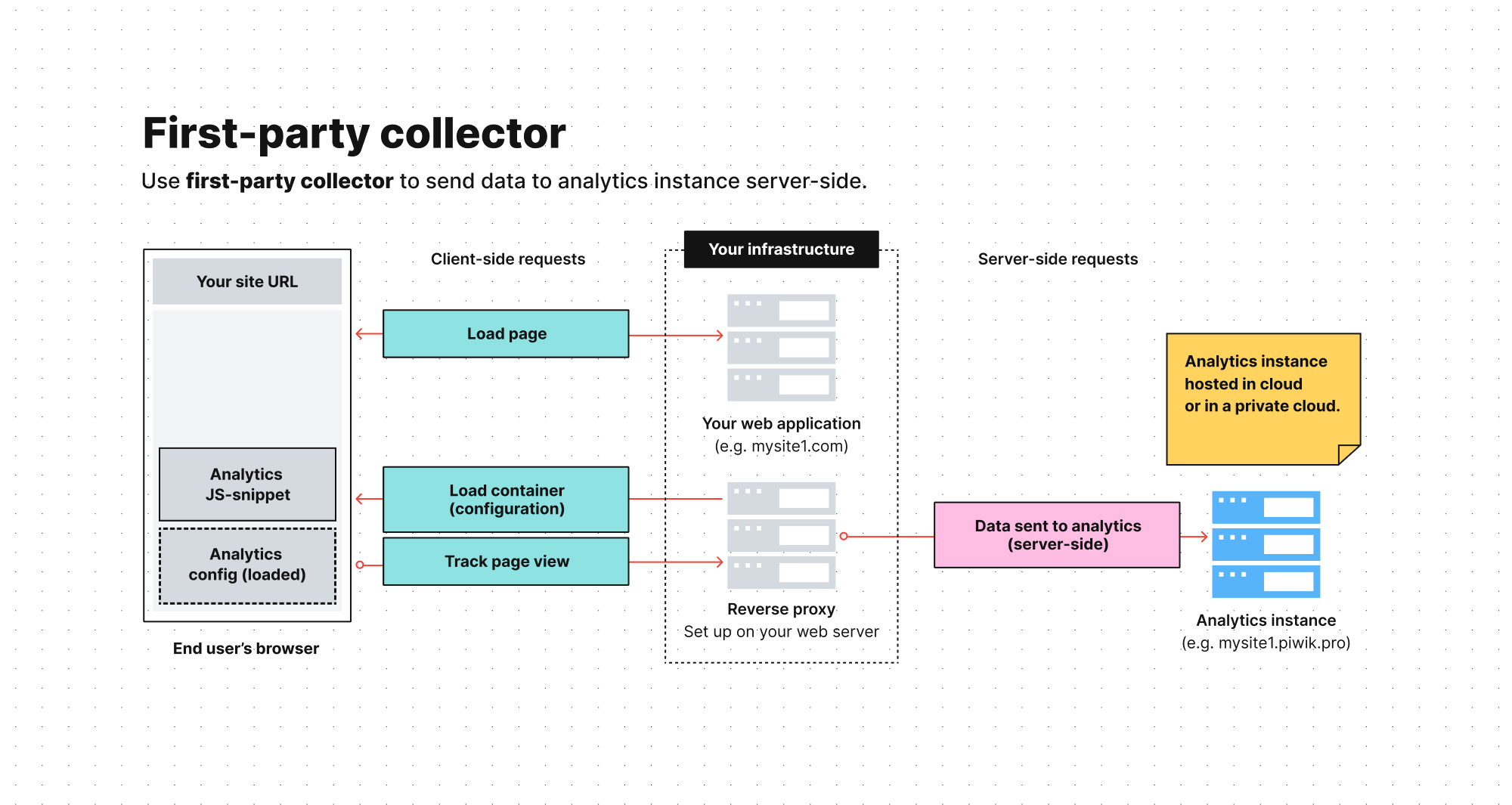
Because the requests to the browsers come from the same domain and IP address as the requests necessary to load your page, the accuracy of the collected data increases. Among other things, this setup can help you improve the longevity of your cookies and avoid many challenges you’d experience with a client-side configuration.
A first-party collector is also easier to manage than a pure server-side setup because you don’t need to integrate with any API or use other manual integration methods. Instead, you can use a ready-made solution developed by a vendor.
Benefits of hybrid server-side tracking with a first-party collector
Higher data accuracy and longer cookie lifespan
It can extend the lifetime of analytics cookies, improving overall data accuracy.
Convenience
When using the hybrid method with a first-party collector, you have the flexibility of client-side setup along with the capabilities provided by the server side. For instance, both your client-side tag manager and your consent are on a first-party domain, making them easier to use compared to other server-side methods.
Rich and high-quality data collection
It provides the same data granularity as client-side tracking, including traffic sources, referring sites, page views, paths taken, conversion rates, real-time data, browser data, scroll depth, and custom events.
Lightweight
It reduces infrastructure impact by not requiring a separate platform or large component deployment.
No reliance on Google products
It helps you avoid using Google server-side Tag Manager or involving Google servers, which is crucial if you want to stay away from US-based products due to privacy concerns and issues with cross-Atlantic data transfers.
GDPR and consent requirement
Despite being mostly undetectable in browsers, server-side tracking still requires user consent for data collection. Data can only be lawfully gathered without consent if it’s anonymized according to GDPR standards. That said, gathering consents with the use of a first-party collector is much more convenient than with the pure server-side solution. It can be done through an integrated client-side consent management platform that helps automatically adjust tracking to visitors’ privacy preferences.

“When it comes to a successful server-side analytics tracking implementation, it’s crucial to choose first-party data collection tools that are compliant with major regulations such as GDPR, PECR or TTDSG. The more sensitive data you collect (for example,in banking, healthcare or government), the more selective you should be with your tools.”
Hamza El Kharraz
Digital Analyst at ANALYGO
Example tools for hybrid server-side tracking:
- Piwik PRO Analytics Suite
- Matomo
- Heap Analytics
- Adobe Analytics (through server-side tagging)
- Google Analytics (through server-side tagging)
- Segment (through server-side tagging)
Important considerations for hybrid server-side tracking with a first-party collector
Complex implementation
Tracking with a first-party collector is simpler than log analytics or pure server-side tracking but still requires time and resources. If you lack internal expertise, consider opting for an analytics vendor with dedicated support and customer care. This will help you with getting started and maintaining your server-side tracking setup.
Applicability to analytics only
The method works only for one piece of your data stack and won’t allow the use of third-party tags. If you want to use all your marketing tools server-side, you might still need to employ other methods such as server-side tagging.
The methods of server-side tagging
Another popular method for server-side data collection is server-side tagging.
Server-side tagging and tracking are related concepts but serve different purposes. While server-side tracking focuses on collecting data about user interactions with a website directly through the server, server-side tagging refers to implementing and managing tracking tags (serving similar purposes as analytics or advertising scripts) on a dedicated tag manager server.
In essence, the difference between them is similar to the difference between an analytics platform and a tag management system.
Pure server-side tagging
Before we explain the concept of pure server-side tagging, let’s describe the standard client-side implementation of a tag manager.
A typical client-side tagging configuration relies on trackers installed directly on the page and sending data to various collection servers, such as your analytics, A/B testing tool, or CRM.
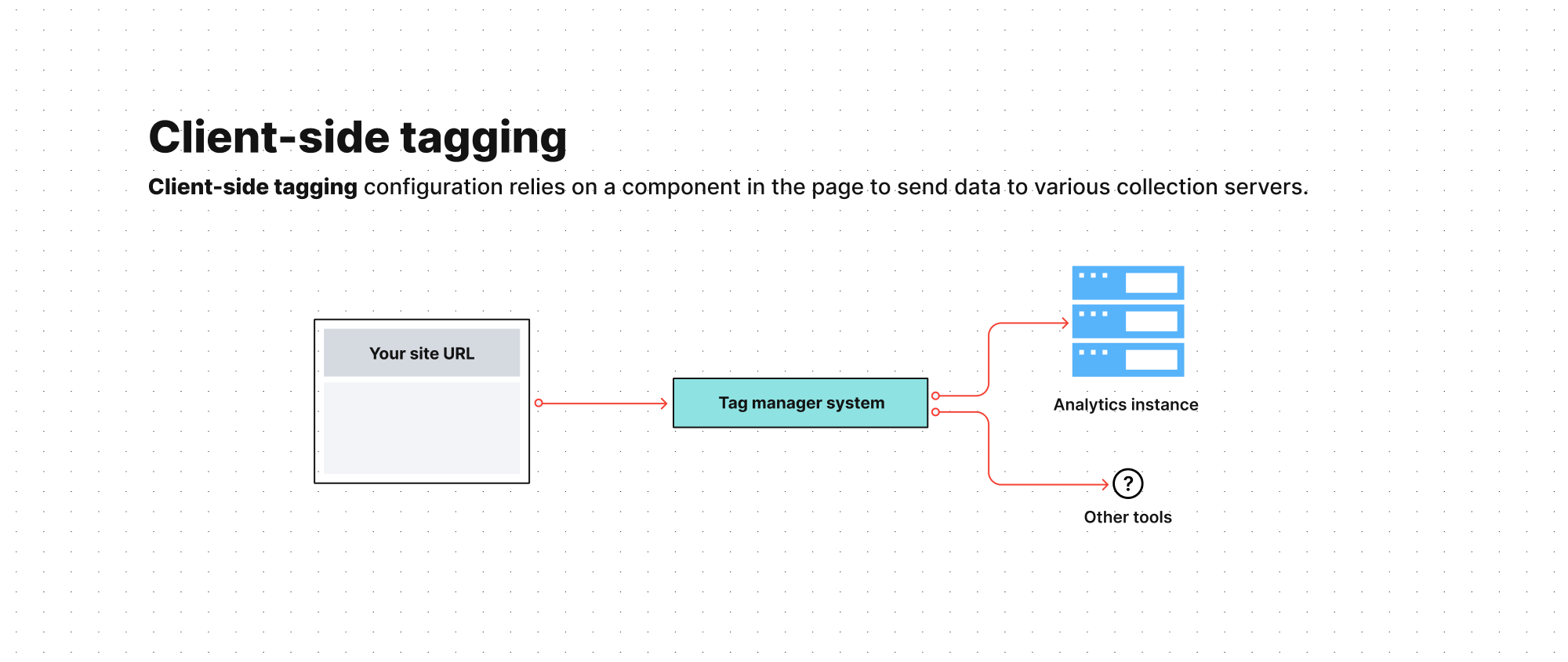
Unlike client-side tagging, server-side tagging uses a dedicated tag manager server to host data and send it to marketing tools. This creates a buffer separating your website and user data from third-party vendors.
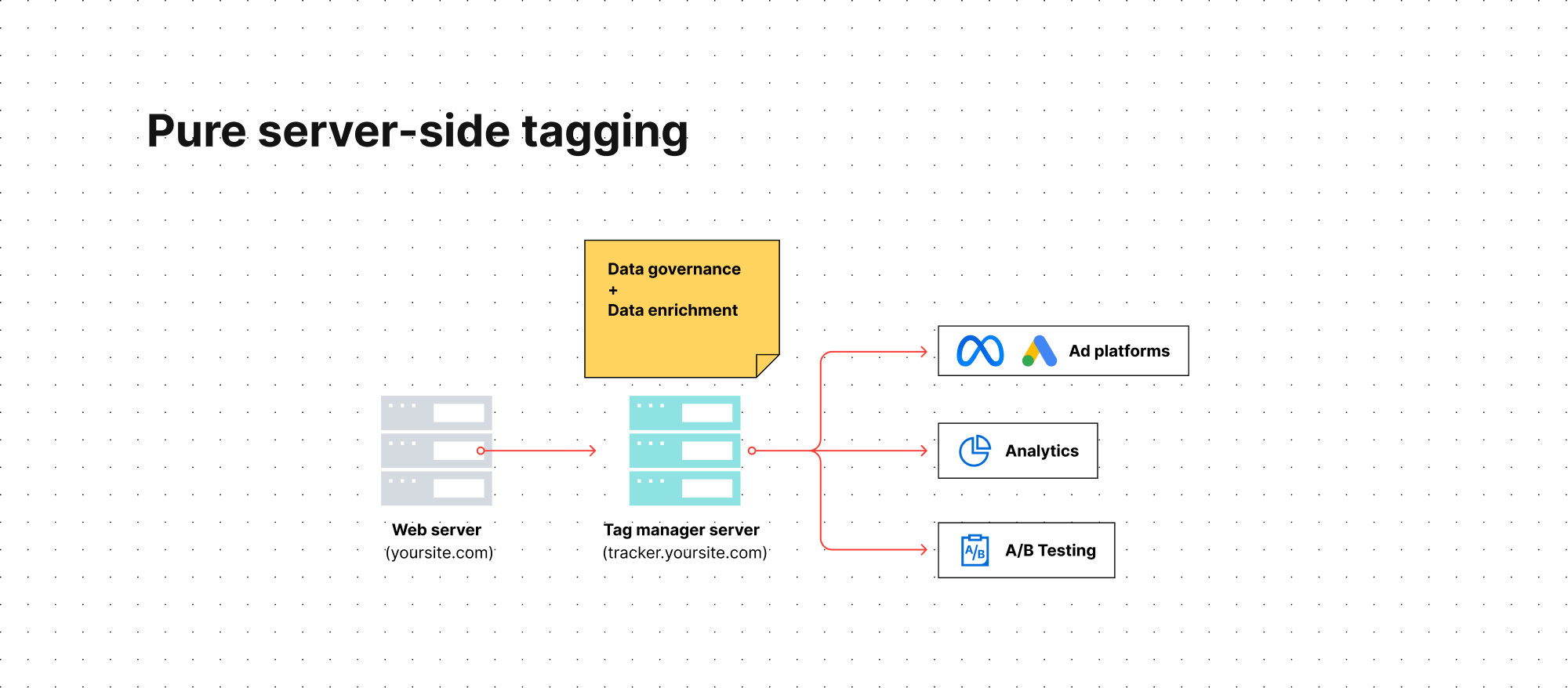
As a result, you gain full control over what types of data you share with your marketing tools. For example, you can choose to avoid passing personal data to certain platforms or hash it before the information reaches the endpoint, enhancing privacy. This configuration also allows you to integrate and enrich your dataset, which can be useful for improving communication with ad platforms and ensuring accurate conversion tracking.
Note however that this method is not the default setup of tools such as Google Analytics 4 as they rely on a hybrid server-side implementation.
Similar to pure server-side tracking, implementing this method requires extensive effort from your technical team. You could do it, for example, by customizing your server-side Google Tag Manager setup to fully exclude the client-side component or by creating your own dedicated solution.
Since it’s done without involving the browser, the data collected this way is much more reliable and accurate than with client-side and hybrid server-side tagging.
To learn more about the benefits and considerations of this method, read the next section.
Example tools for pure server-side tagging: Google Analytics 4 with server-side GTM in custom deployment and your own solutions.
Hybrid server-side tagging
Server-side tagging offered by tools like Google Tag Manager or Jentis is a hybrid data collection method.
It shares many benefits with a pure server-side tagging deployment, and is easier to implement since you can rely on ready-made products and integrations provided by the vendors. Because of that, it’s much more popular than pure server-side deployment.
However, the key difference comes from its hybrid approach. Server-side tag management leans heavily on a client-side component. In the standard configuration of tools such as Google Analytics 4, the tracking request starts with a client-side tag manager before moving to its server-side counterpart.
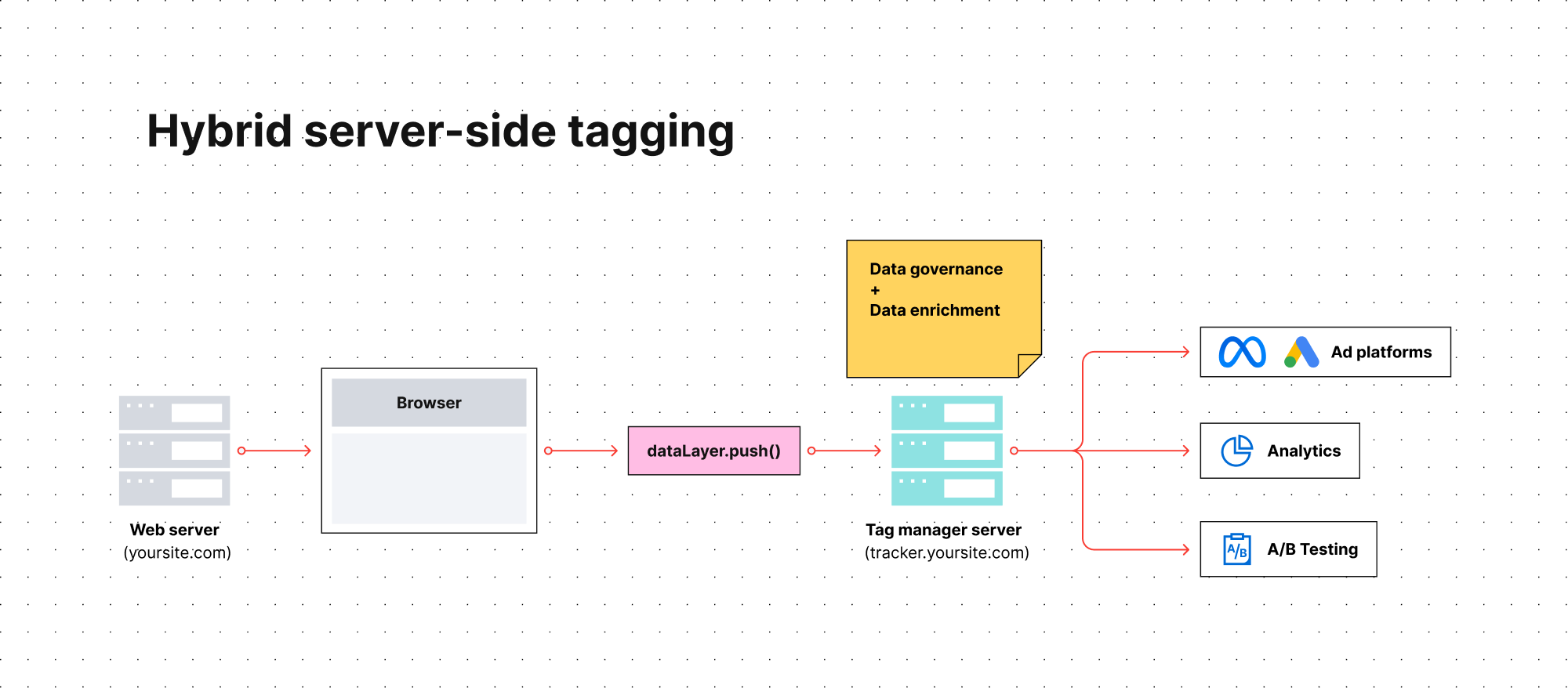
This means that, despite better control over data, your data collection could still encounter issues similar to those present with traditional client-side tagging.
WEBINAR
Watch a free webinar recording
A practical guide to server-side tagging with Piwik PRO
Thinking about implementing server-side tag management but not sure if it’s the right choice for you? Watch our webinar, during which experts Simo Ahava and Antoni Bartczak have an open discussion about the key concepts and practical uses of server-side tagging.
Speakers
Simo Ahava, Antoni Bartczak

Benefits of hybrid server-side tagging
Data governance
By managing tags on the server side, organizations have greater control over what data is collected and shared. For example, you can decide to mask, remove, or anonymize specific data elements, such as IP addresses, before sending data to a specific third-party platform. This reduces the risk of unauthorized data access.
Cleaner data
Server-side tagging allows you to filter out unnecessary or redundant data before it reaches vendors. This results in cleaner and more accurate datasets.

“Server-side tagging gives you more control over the data before sending it to the final destination. It lets you filter or hash specific information, such as PII. It also enables you to enrich the data with information that you don’t want to make visible on the front end, such as your product margins.”
Timo Dechau
Founder, Tracking & Analytics Engineer at Deepskydata
Improved website performance
It reduces the number of tags that run on the website, improving your website’s performance.
Data enrichment
It allows you to enrich incoming data with information from different tools, such as your CRM or transactional system.
Extended cookie lifetime
Because the cookies are set from your website subdomains, this method often improves cookie lifespan and helps you collect more reliable data compared to standard client-side tag management systems.
“Everybody can benefit from server-side tagging, but the impact on small websites might not be big enough to justify the cost and resources required to set up and maintain it. Meta, Pinterest, Google and other Big Tech companies are now recommending, or I should say, demanding, marketers to implement server-side tagging to take full advantage of the remarketing and retargeting capabilities. So it has become essential for them. If an organization has reached analytics maturity and data is used for critical decisions, investing in server-side setup might bring significant advantages.”
Anil Batra
Digital Data and Analytics Advisor, CEO at Optizent
Important considerations for server-side tagging
Privacy compliance
Like other methods, server-side tagging requires visitor consent to collect personal data, such as unique IDs. If you choose to do data enrichment or send conversion data to different platforms, you’ll also need separate consents for each purpose, which can be difficult to obtain. Anonymizing data might allow you to collect insights without the need for consent, but it significantly limits the value of the data.
Learn more about obtaining server-side cookie consent.
Complex implementation
Server-side tagging calls for a specialized tag management system and installation and maintenance of a server or cloud-based database. This requires additional work from technical teams. It becomes even more difficult when you decide to implement pure server-side tagging.
“Server-side tagging can be a great opportunity for businesses to overcome some data collection hurdles inherent to tracking on the browser, like the impact of ad blockers and the phasing out of third-party cookies, to name but a few. However, the learning curve can be steep, and there are hidden costs, such as hiring experts to maintain infrastructure that should be taken into account.”
Hamza El Kharraz
Digital Analyst at ANALYGO
Costs
This method introduces additional server costs, which depend on the volume of data processed.
Limited support
Ensure that your data stack tools support server-side tagging before investing in the solution. Not all marketing vendors have integrated tags for this technology.
Less accurate data compared to other methods (applies to hybrid server-side tagging)
Hybrid server-side tagging still relies on a client-side component, so it faces similar challenges to a standard tag manager setup. This can lead to more fragmented data compared to methods that use a pure server-side configuration.
Experts opinion
Timo Dechau
Founder, Tracking & Analytics Engineer at Deepskydata
I see only limited use cases for server-side tagging. If you use an analytics solution that gives you less control over what data is sent in which form, you can use a server-side Google Tag Manager to remove or hash this information. While some enrichment use cases may also be valid, I prefer to do enrichment in the data warehouse.
Think of server-side tagging as another block in your system. You must guarantee it’s up and running 100% of the time, because when it’s down, you lose your data. By choosing this tracking method, you also increase the complexity of your setup. Finding tracking issues will become more complicated, and so will adding new components to the tracking.
Server-side tagging tools and services
- Google Server-Side Tag Manager (sGTM)
- Segment
- Adobe Analytics
- Jentis
Server-side tracking vs. server-side tagging: A quick comparison
| Pure server-side tracking | Hybrid server-side tracking | Pure server-side tagging | Hybrid server-side tagging | Client-side tagging | Client-side tracking | |
|---|---|---|---|---|---|---|
| Data quality and reliability | ||||||
| Extended cookie lifetime | ||||||
| Ease of use | ||||||
| Privacy compliance | Depends on your setup | Depends on your setup | Depends on your setup | Depends on your setup | Depends on your setup | Depends on your setup |
| Ability to send data to multiple marketing tools |
Common misconceptions around server-side tracking and tagging
While server-side tracking and tagging can enhance data reliability and address some client-side issues, they are not a universal solution to all problems related to modern data collection. Here are some examples of use cases where server-side tagging and tracking won’t or shouldn’t be the answer.
Going server-side allows you to disobey privacy regulations and user choices
All server-side tracking and tagging methods improve data reliability and work around client-side limitations. However, while some server-side trackers might not be visible in browsers, they shouldn’t be used to deceive users or to get around consent requirements for data collection. Following privacy regulations such as GDPR, TDDDG, and PECR, and respecting user choices, is vital for maintaining customer trust and establishing lasting business relationships.
Server-side tracking is a great alternative to third-party tracking
Despite the popular belief, switching to server-side tracking doesn’t resolve one of today’s most pressing marketing issues: the deprecation of third-party cookies. While server-side tracking and tagging can improve the quality of your first-party data, they don’t directly address concerns related to third-party cookies.
As third-party cookies are phased out, retargeting anonymous visitors across different sites becomes increasingly difficult. The alternative involves sending personal data, such as hashed emails or addresses, to ad platforms without involving the browser.
While this method can significantly boost your data accuracy, using it without explicit user consent is illegal. Obtaining that consent can be extremely challenging, making it a tough hurdle to clear despite the potential benefits.
Learn more about the best privacy-compliant data strategies for the so-called “cookieless future”: Here is all you need to know about the end of third-party cookies.
How to implement server-side tracking and tagging with Piwik PRO
Server-side tracking and tagging offer robust alternatives to traditional client-side methods, enhancing data quality, security, and control. However, implementing these solutions requires technical expertise and compliance with privacy regulations.
Piwik PRO Analytics Suite is a privacy-first platform that offers advanced analytics capabilities. The suite consists of tightly integrated Analytics, Tag Manager, Consent Manager, and Customer Data Platform. It also easily connects with other parts of your tech stack, letting you integrate and activate data across all your marketing tools.
When it comes to server-side tracking and tagging with Piwik PRO, you can take advantage of the following methods:
- Pure server-side tracking – this can be done using Piwik PRO’s API and SDK.
- Hybrid server-side tagging with sGTM – a great solution for companies that want to pair Piwik PRO Analytics with Google Tag Manager. It’s available in both the Business and Enterprise plans.
- Hybrid server-side tracking with a first-party collector – it’s a great option for companies looking to move their analytics tracking server-side. With native integration with Piwik PRO Consent Manager and Cookie Information CMP, you’ll be able to adjust your tracking to your visitors’ privacy preferences. It also allows you to employ various data anonymization methods to make sure you collect valuable data even when visitors don’t consent to tracking. It’s available in the Enterprise plan.
- Hybrid server-side tagging through integration with Jentis – a more privacy-friendly but powerful alternative that doesn’t require using any of Google’s products. It’s available in Business and Enterprise plans.
The Enterprise plan for Piwik PRO Analytics Suite comes with dedicated support and customer care to help you get the most out of your server-side tracking or tagging project.
FAQ
What is server-side analytics tracking?
Server-side analytics tracking is a data collection method in which all the tracking and data collection from your website or app happens on a server instead of in your web browser. The server then sends this data to your analytics platform to generate reports and dashboards.
What is server-side tagging?
Server-side tagging is a data collection method that uses a dedicated server to manage and host tracking tags, then sends the data to marketing tools. This setup creates a buffer between your website and third-party vendors, which gives you better control over what kinds of data you share with each marketing platform.
Is server-side tracking a cookieless method?
Server-side analytics tracking is often considered cookieless because it doesn’t rely on browser cookies to monitor user actions. However, many server-side tagging and tracking solutions, such as sGTM, Matomo, Piwik PRO, or Jentis, still utilize cookies – just in a different way compared to client-side tracking.
What is log analytics?
Log analytics is the process of analyzing log data from your website and is often considered one of the first methods for server-side tracking. This approach allows you to import server-side logs using specialized software that interacts with the web server. It enables you to retrieve records that match specific criteria, identify trends, and analyze patterns.
However, the information collected through server logs is relatively limited compared to data gathered via client-side JavaScript. Server logs lack essential data points such as browser plugins, screen resolutions, and page titles, which may be useful for your analysis. Additionally, they make it challenging to identify visitors, as server logs don’t store information about user IDs stored in cookies set in their browsers.

